
NVIDIA GPUs are hotter than ever, with demand far outpacing supply. Since the release of the A100 in 2020, NVIDIA has kept pushing the limits of AI and data center performance. The H100 followed in 2022, then the L40S in 2023, and 2024, the H200.
Each of these GPUs serves a different purpose, from AI training to cloud workloads and enterprise applications.
- If you need AI training and HPC, go for H100 or H200
- For AI inference and visualization, choose L40S
- for a cost-effective AI powerhouse, the A100 still holds strong.
But with so many options, which one is right for your needs? Let's break it down in a way that actually makes sense.
Server Platform Options
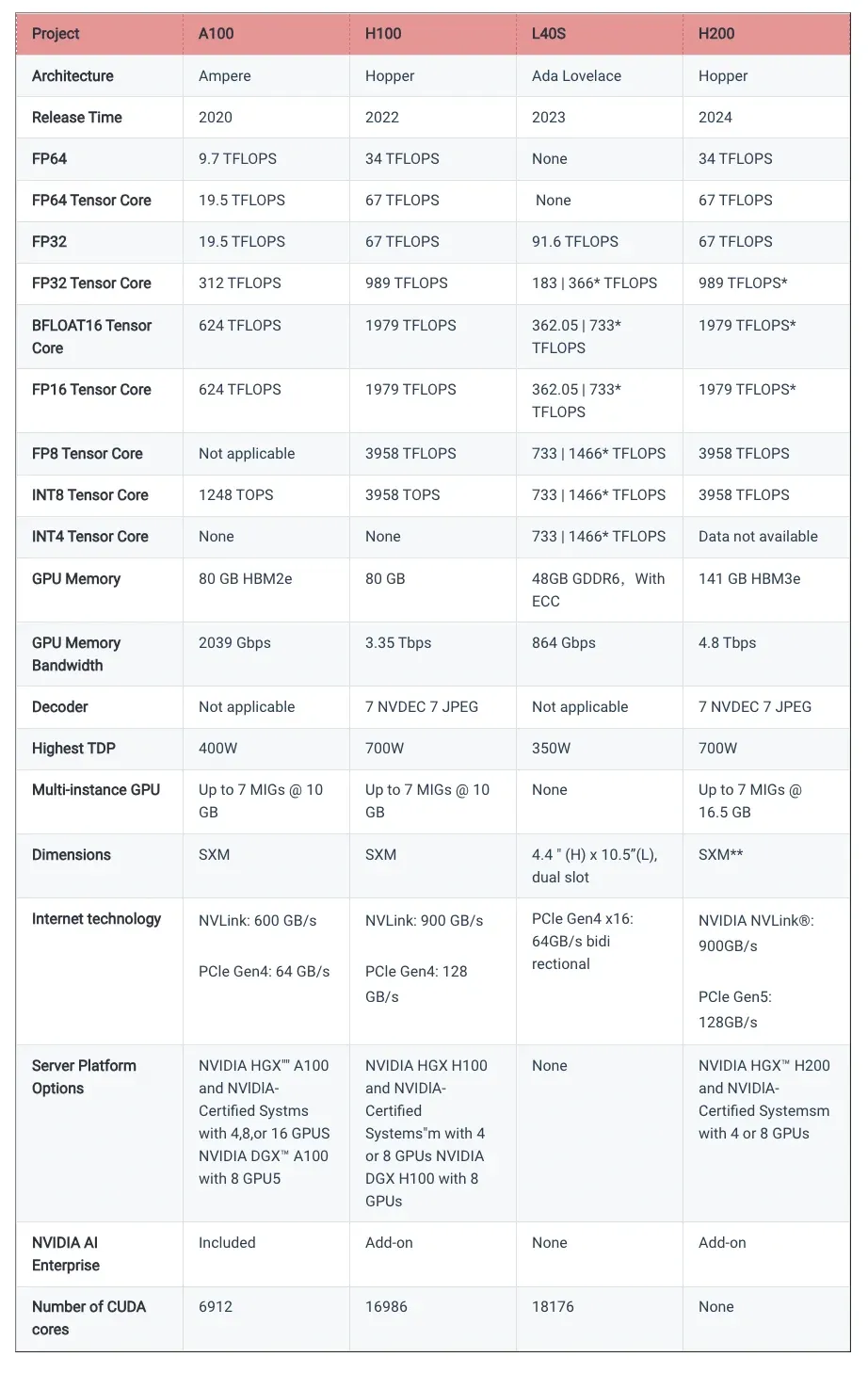
NVIDIA’s A100, H100, L40S, and H200 GPUs are built for different workloads, from AI training to enterprise applications.
-
The A100 and H100 come in NVIDIA HGX and DGX systems, while the L40S is a standalone option without a dedicated platform.
-
The H200, the latest in the lineup, follows the H100’s setup with HGX and Certified Systems.
-
When it comes to raw power, the CUDA core count jumps from 6,912 in the A100 to 16,986 in the H100 and 18,176 in the L40S, with the H200 expected to be even more powerful.
Whether you need AI acceleration, cloud computing, or enterprise solutions, there’s an NVIDIA GPU built for the job.
The A100

The A100, launched in 2020, was NVIDIA’s first GPU built on the Ampere architecture, delivering major performance upgrades.
Before the H100 arrived, the A100 was the undisputed leader, thanks to enhanced Tensor cores, a higher CUDA core count, improved memory, and a blazing-fast 2 Tbps memory bandwidth.
One of its standout features is Multi-Instance GPU (MIG), which allows a single A100 to be split into multiple smaller, independent GPUs. This makes it a game-changer for cloud and data center environments, optimizing resource efficiency.
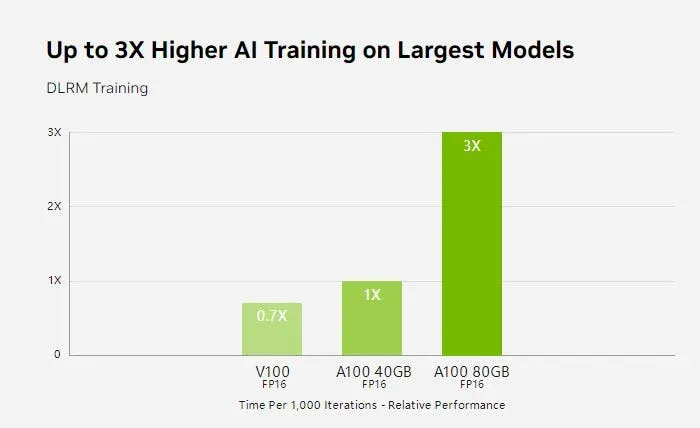
Even though newer models have surpassed it, the A100 is still a strong choice for AI training, deep learning, and complex neural networks. Its Tensor cores and high throughput make it a reliable performer in these fields.
It also shines in AI inference, speech recognition, image classification, recommendation systems, big data processing, scientific computing, and even high-performance applications like genomic sequencing and drug discovery.
The H100

The H100 is designed to handle the most demanding AI workloads and large-scale data processing tasks, making it a powerhouse in high-performance computing.
With upgraded Tensor cores, the H100 delivers a significant boost in AI training and inference speeds, supporting a wide range of computations, including FP64, FP32, FP16, and INT8.
This flexibility allows it to efficiently process everything from high-precision scientific simulations to fast, low-latency AI inference tasks.
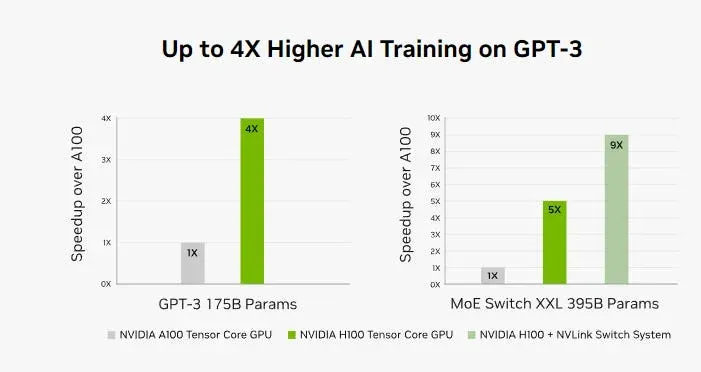
Compared to its predecessor, the A100, the H100 achieves up to 6× faster FP8 computation, reaching an impressive 4 petaflops of processing power. It also comes with 50% more memory, leveraging HBM3 high-bandwidth memory, which provides a 3 Tbps bandwidth and nearly 5 Tbps external connectivity speed.
Additionally, NVIDIA's new Transformer engine accelerates model training by up to 6×, making it an excellent choice for training massive AI models more efficiently.
While both the H100 and A100 are widely used in AI training, inference, and scientific computing, the H100 stands out when handling extremely large AI models and complex simulations.
Its advanced architecture makes it particularly well-suited for real-time AI applications, such as advanced conversational AI, real-time translation, and other high-speed, responsive AI systems.
In summary, the H100 surpasses the A100 in AI speed, memory capacity, and scalability, making it the superior choice for enterprises and researchers working on cutting-edge AI models and high-performance computing applications.
The L40S

The L40S is engineered to power next-generation data center workloads, excelling in generative AI, large language model (LLM) training and inference, 3D rendering, scientific simulations, and high-performance computing.
Designed to meet the growing demands of AI-driven applications, the L40S delivers exceptional computational capabilities across a variety of industries, from cloud computing to enterprise AI solutions.
When compared to previous-generation GPUs like the A100 and H100, the L40S provides up to 5× faster inference performance and 2× better real-time ray tracing (RT) performance, making it particularly well-suited for AI-based graphics applications, digital content creation, and large-scale AI model deployments.
With 48GB of GDDR6 memory and ECC (Error Correction Code) support, the L40S ensures data integrity, a critical factor in high-performance computing environments.
Additionally, it features over 18,000 CUDA cores, designed to handle complex parallel processing tasks efficiently, making it a versatile choice for workloads that demand both speed and precision.
The H200

The H200 is NVIDIA’s latest GPU, shipping since Q2 2024, and it pushes performance to new heights.
It’s the first GPU to feature 141GB of HBM3e memory with a 4.8 Tbps bandwidth, offering nearly twice the memory and 1.4× the bandwidth of the H100.
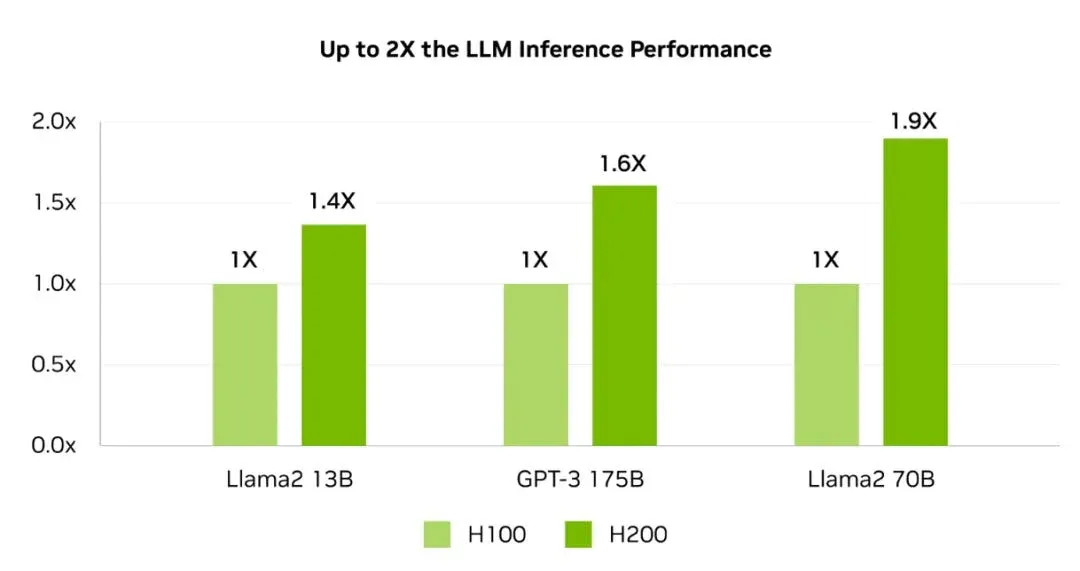
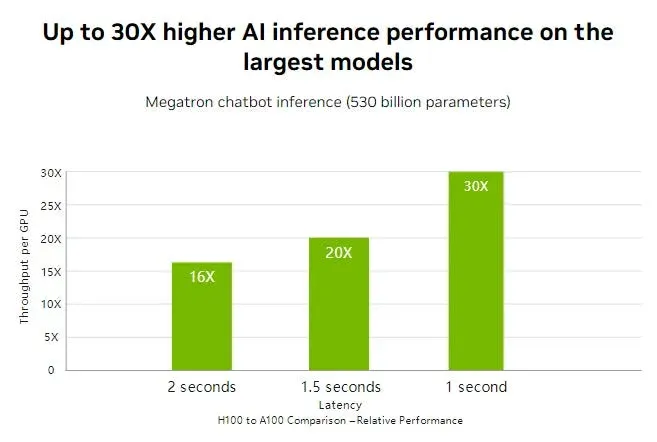
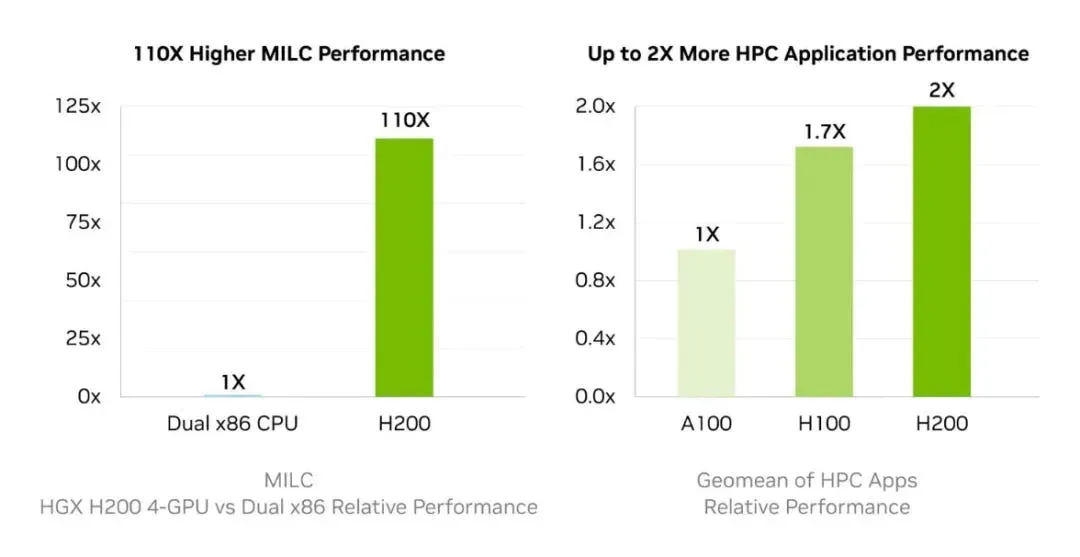
For high-performance computing (HPC), the H200 delivers up to 110× faster acceleration than CPUs, enabling faster results. When running Llama2 70B inference, it doubles the speed of the H100, making it a powerhouse for large-scale AI workloads.
Beyond AI, the H200 plays a major role in edge computing and AIoT (Artificial Intelligence of Things), expanding its impact beyond traditional data centers.
Expect the H200 to lead in training and inference for the largest AI models (17.5B+ parameters), generative AI, and high-performance computing (HPC). With unmatched memory, bandwidth, and inference speed, it’s the go-to choice for cutting-edge AI applications.















